18CSE484T - Deep Learning Unit 4 & 5 (12 MARKS)
12M:
Transfer Learning
Transfer learning:
Transfer learning is the reuse of a pretrained model on a new problem
In transfer learning, a machine exploits the knowledge gained from a previous task to improve generalization about the other
Transfer learning has the benefit of decreasing the training time for a neural network model and resulting in lower generalization error
Sometimes it takes days or even weeks to train a deep neural network from scratch on a complex task. Transfer learning decreases the task substantially
How it works:
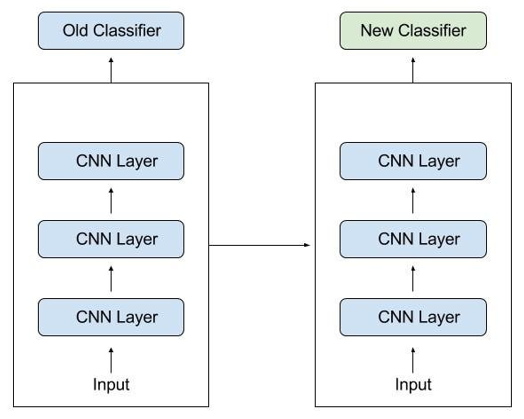
In transfer learning, the early and middle layers are used and we only retrain the latter layers
When to use transfer learning:
There isn’t enough labeled training data
There already exists a network that is pretrained on a similar task
When task 1 and task 2 have the same input
Implementing transfer learning:
Two main approaches:
Weight initialization
Training a model to reuse it
Using a pretrained model (select source model, reuse model, tune model)
Feature extraction (AKA representation learning)
Benefits of using transfer layer:
Higher start
Higher slope
Higher asymptote
Architecture of AlexNet used for image classification.
AlexNet:
It was proposed in 2012 and won the Image-net large scale visual recognition challenge in 2012
It has eight layers with learnable parameters
The model consists of five layers with a combination of max pooling followed by three fully connected layers
They use Relu activation function in each of these layers except the output layer
It is found out using Relu activation function increased the speed of training time by almost six times
They also use dropout layers, that prevented the model from overfitting
The model is trained on the ImageNet dataset. The dataset has almost 14 million images across a thousand classes
AlexNet Architecture:
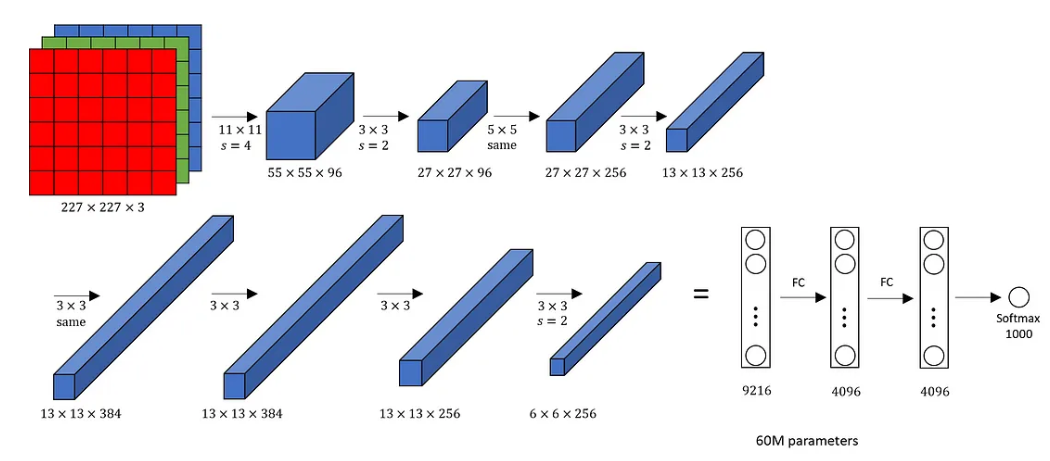
The 1st is a convolution layer with 96 filters of size 11 x 11 with stride 4. The activation function used is Relu. the output feature map is 55 x 55 x 96
The next is a max pooling layer with size 3 x 3 and stride 2. The output feature map is 27 x 27 x 96
The second convolution used 256 filters with reduced size 5 x 5. The stride is 1 and padding is 2. The activation function used is again Relu. The output feature map is 27 x 27 x 256
The next is a max pooling layer with size 3 x 3 and stride 2. The output feature map is 13 x 13 x 256
The 3rd convolution uses 384 filters with stride and padding 1. The activation function is Relu. The output feature map is 13 x 13 x 384
The 4th convolution uses 384 filters with stride and padding 1. The activation function is Relu. The output feature map is 13 x 13 x 384 and remains unchanged
Then we have the final convolution layer with 256 filters with size 3 x 3. The stride and padding is 1. The activation function is Relu. The output feature map is 13 x 13 x 256
Then the third max pooling layer of size 3 x 3 and stride 2 is applied. The output feature map is 6 x 6 x 256
The first dropout layer comes with dropout rate as 0.5
Then 1st fully connected layer with output size 4096
Again dropout with rate as 0.5
Then 2nd fully connected layer with output size 4096
Last fully connected layer with 1000 neurons and activation function used is Softmax
This has a total of 62.3 million learnable parameters
Video captioning using 3D-CNN:
3D-CNN has some unrelated content in the ppt...I had to use chatgpt to get the answer for 4m. So I am not taking answer for this question
How the RMSProp and SGD optimizers used in RNN and CNN respectively to improve the learning process.
Optimizers in Deep Learning:
Optimizers are algorithms or methods used to minimize the loss function or to maximize the efficiency of production
They are mathematical functions that are dependent on the model’s learnable parameters
They help to know how to change weights and learning rate of neural networks to reduce the losses
Types of optimizers:
Gradient descent
Stochastic gradient descent
Mini-batch gradient descent
SGD with momentum
RMSprop
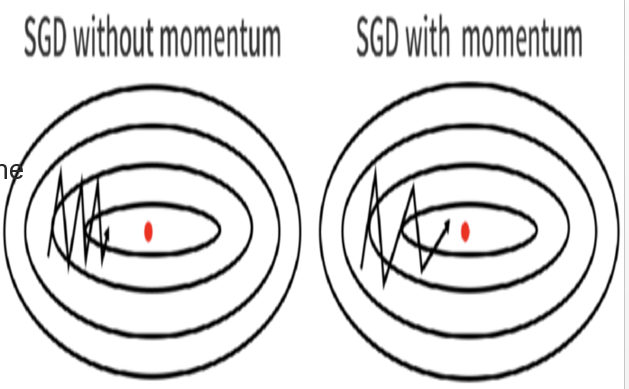
SGD with momentum:
It is a stochastic optimization method that adds a momentum term to regular stochastic gradient descent
Momentum stimulates the inertia of an object
The direction of the previous update is retained to a certain extent and the current update gradient is used to fine tune the direction of the final update
Advantages:
Reduce noise
Smoothen curve
Learn faster
Get rid of local optimization
Disadvantages:
Extra hyperparameter is added
RMSProp:
It is a special version of AdaGrad in which the learning rate is an exponential average of the gradients instead of the cumulative sum of squared gradients
RMSprop basically combines momentum with AdaGrad
Advantages:
Learning rate gets adjusted automatically
Different learning rate for each parameter
Noise handling
Disadvantages:
Slow learning
Hyperparameter tuning
Performance variability due to sensitivity
Autoencoder applications 1. Denoising 2. Anomaly detection
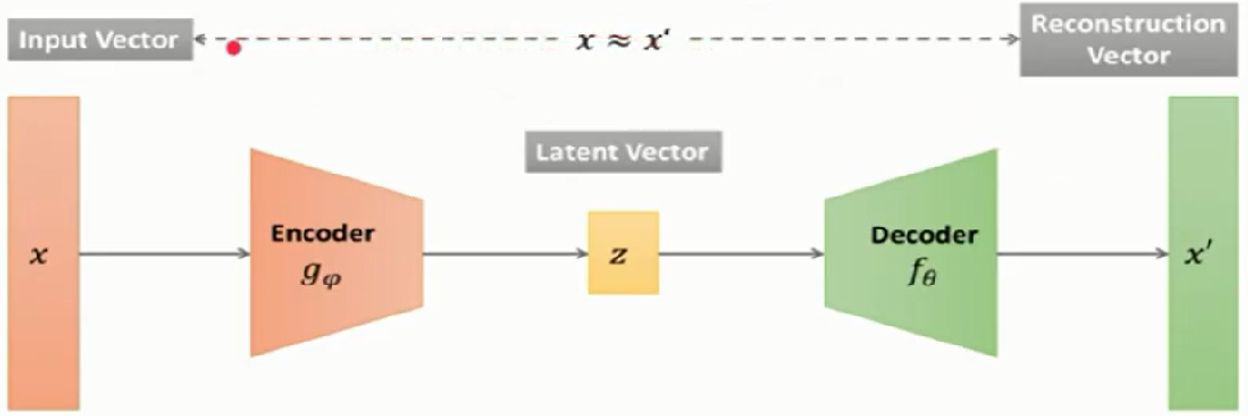
Autoencoder:
An autoencoder is a type of artificial neural network used to learn efficient dat codings in an unsupervised manner
Applications:
Image reconstruction
Image colorization
Image generation
Image denoising
Anomaly detection
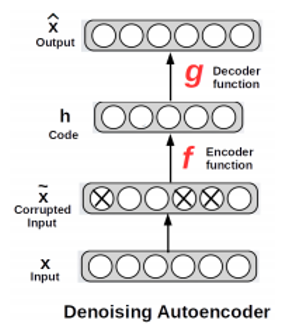
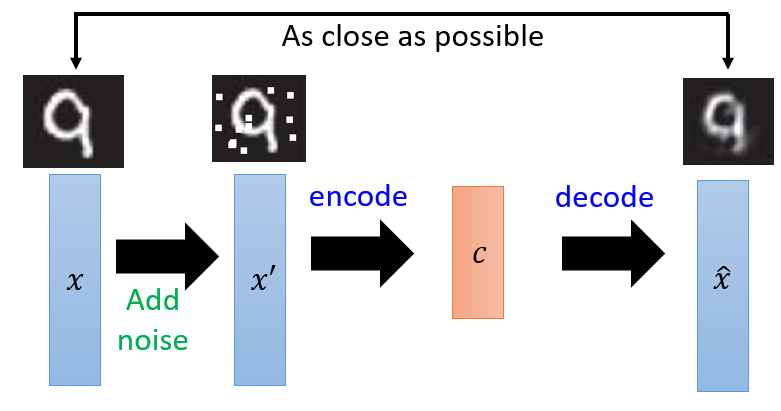
Image denoising:
When our image gets corrupted or there is a bit of noise in it, we call this image a noisy image.
We apply a Denoising autoencoder to remove (if not all)most of the noise of the image.
Denoising autoencoder:
To learn useful features, random noise is added to the inputs and makes the autoencoder to recover the original noise-free data
The autoencoder subtracts the noise and produces the underlying meaningful data. This is called a denoising autoencoder
It makes the model robust against noisy / incomplete inputs
Simpler to implement
Requires adding one or two lines of code to regular autoencoder
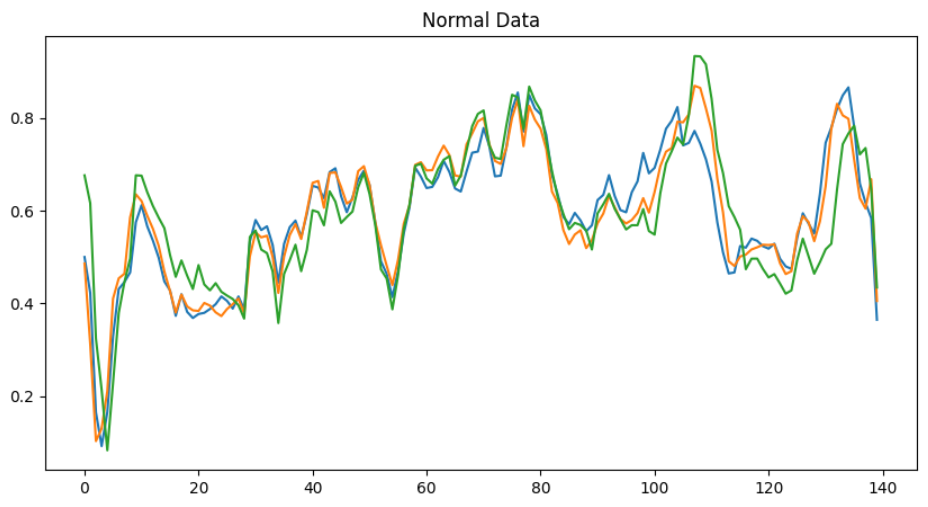
Anomaly detection:
ECG5000 - dataset
No of classes - 5
Normal data:
Anomaly data:
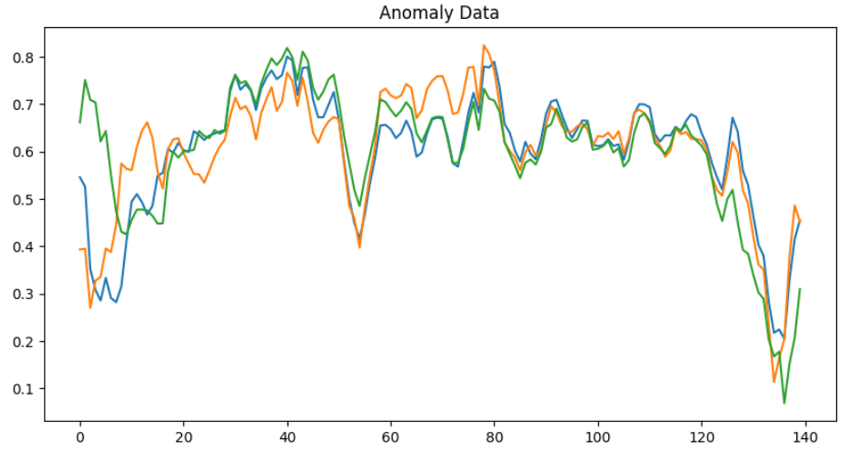

Siamese networks and its applications
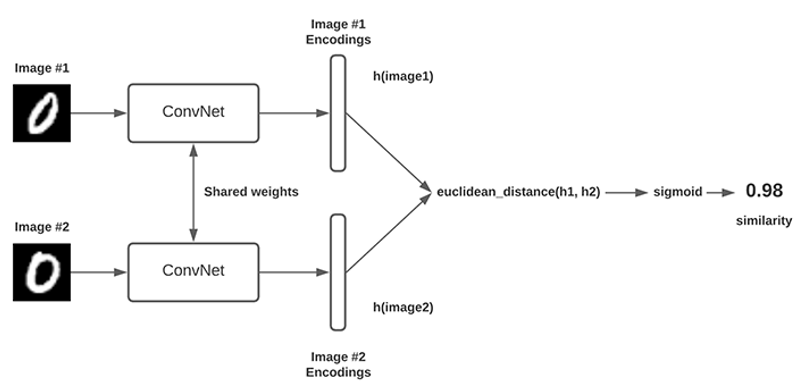
Siamese networks:
A Siamese neural network is also called a twin neural network
It is an ANN which contains two or more identical subnetworks which means they have the same configuration with the same parameters and weights
Usually, we only train one of the subnetworks and use the same configuration for other sub-networks
These networks are used to find the similarity of the inputs by comparing their feature vectors
We will have two encodings F(A) and F(B) and we will compare them to know how similar they are
How to compare vectors F(A) and F(B):
Simply measure the distance between the two vectors
If the distance is small, then the vectors are similar and if distance is large, then the vectors are very different from one another
We can define a distance function
When A and B are the same person, d(A,B) is small and when A and B are different person, d(A,B) is large
Loss function:
When A and B are positive pair, the loss function is L2 norm
For negative pairs, we use a different kind of loss function called hinge loss
Sample:
Applications:
- image classification
- text classification
- sound classification
- feature encoding
- object detection



Comments
Post a Comment