18CSE484T - Deep Learning Unit 4 & 5 (4 MARKS)
4M:
Regularized autoencoder:
Undercomplete autoencoders can fail to learn anything useful if the encoder and decoder are given too much capacity
Unlike those, Regularized autoencoders use a loss function that encourages the model to have other properties besides the ability to copy its input to its output
Sparsity of the representation
Robustness to noise or to missing inputs
Smallness of the derivative of the representation
Types of regularized autoencoder:
Sparse autoencoder
Denoising autoencoder
Compare and contrast autoencoder vs CNN
Autoencoders:
Learn a compact representation of the dat for reconstruction
Typically consists of fully connected layers
It is an unsupervised learning technique
Applicable to general purpose tasks
CNN:
Extract hierarchical features from images for classification or other tasks
Consists of convolutional, pooling and fully connected layers
It is a supervised learning technique
Specialized for image related tasks
While both autoencoders and CNNs learn representations, autoencoders focus on data compression and reconstruction whereas CNNs specialize in extracting features from images for classification and other visual tasks
Applications of autoencoders
An autoencoder is a type of artificial neural network used to learn efficient dat codings in an unsupervised manner
Applications:
Image reconstruction
Image colorization
Image generation
Image denoising
Image compression
Anomaly detection
Dimensionality reduction
Sequence to sequence prediction
Recommendation system
Undercomplete autoencoder
An autoencoder whose code dimension is smaller than the input dimension is called under complete
When the encoder and decoder are linear and L is the mean squared error, an under complete autoencoder learns to span the same subspace as PCA
Under complete autoencoders do not need any regularization as they maximize the probability of the data rather than copying the input to the output
Has a smaller dimension for hidden layer compare to the input layer and this helps in obtaining important features from the data
Objective is to minimize the loss function by penalizing the g(f(x))
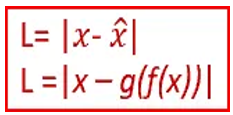
Dimensionality reduction by autoencoder
An autoencoder whose code dimension is smaller than the input dimension is called under complete
The size of the hidden layer is smaller than the input layer
We force the network to learn important features by reducing the hidden layer size
Dimensional reduction methods are based on the assumption that dimension of data is artificially inflated and its intrinsic dimension is much lower
Siamese networks:
A Siamese neural network is also called a twin neural network
It is an ANN which contains two or more identical subnetworks which means they have the same configuration with the same parameters and weights
Usually, we only train one of the subnetworks and use the same configuration for other sub-networks
These networks are used to find the similarity of the inputs by comparing their feature vectors
We will have two encodings F(A) and F(B) and we will compare them to know how similar they are
RCNN - Object Detection
Region Based Convolutional Neural Network uses a Selective Search algorithm to detect possible locations of an object in an image
Steps followed in RCNN to detect objects:
Take a pre-trained CNN
Then this model is restrained. We train the last layer of the neural network based on the number of classes that need to be detected
Next is to get the Region of Interest for each image and reshape the region to match with CNN input size
After getting the regions, we train the SVM to classify the objects and the background
Finally we train a linear regression model to generate tighter bounding boxes for each identified object in the image
3D CNN – Event detection
3D-CNNs are an extension of traditional 2D-CNNs specifically designed for video and spatiotemporal data
Key features:
Temporal axis
3D filters
Integration of motion information
Feature extraction and classification
Video event detection:
3D-CNNs are used to extract spatial features from video frames
Subsequent layers predict events and their locations

Comments
Post a Comment