18CSE359T - NATURAL LANGUAGE PROCESSING UNIT 1 - 4M
4M:
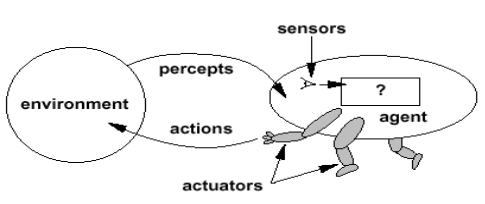
Explain in detail the various steps in NLP

Syntactic analysis is the process of analyzing natural language with the rules of a formal grammar
Semantic analysis is the process of understanding the meaning and interpretation of words, signs and sentence structure
Morphology and types with example
Morphology:
Morphology is the domain of linguistics that analyzes the internal structure of words
Terms:

Types:
Inflection: after adding the suffix, be in the same word class
Eg: Horse - Horses
Eat - Eating
Like - Likes
Derivation: after adding the suffix, change to another word class
Eg: happy (adj) - happi + ness (noun)
Nation / national/ nationalist/ nationalism
What is lemmatization and why is it preferred over stemming?
Lemmatization refers to the morphological analysis of words, which aims to remove inflectional endings
It helps in returning the base or dictionary form of the word, known as lemma
Eg: going/went/goes - go
Why lemma is better?
Stemming algorithm works by cutting the suffix from the word
Lemmatization returns the lemma, base form of the word
Stemming is a general operation while lemmatization is an intelligent operation where the proper form will be looked in the dictionary
Hence lemmatization helps in forming better machine learning features
What is POS tagging? Steps to pick the right POS
The POS tagging problem is to determine the POS tag for a particular instance of a word
POS - Parts of Speech

Methods to assign POS to words:
Rule based tagging
Learning based:
Stochastic models: HMM tagging, maximum entropy tagging
Rule learning: transformation based tagging
Various types of language models
Broadly two types:
Statistical language models: these models use traditional statistical methods and certain linguistic rules to learn the probability distribution of words
Neural language models:
Pure statistical models:
N-grams
Exponential models
Skip-gram models
Neural models:
Recurrent neural networks
Transformer-based models
Large language models
I prefer bigrams over 7 grams. Justify
N-grams:
They are basically a set of co-occurring words within a given window and move one word forward when computing the n-grams
Applications:
Machine translation
Speech recognition
Spell correction
Bigrams:
If a model considers only the previous word to predict the current word, then its called bigram
7-grams:
If the model considers the previous 6 words
Why better?
7-grams has a lot of drawbacks like sparsity, high computational cost and diminishing returns
But bigrams have advantages like reduced complexity and captures local context
Multiword Expression
MWE:
Crosses word boundaries
Is lexically, semantically, syntactically, pragmatically and/or statistically idiosyncratic
Eg: traffic signal, green card, kick the bucket, spill the beans
A large fraction of words in English are MWEs (41%)
Conventional grammars and parsers fail
Idiosyncrasies:
Statistical: traffic signal, good morning (semantically decomposable)
Lexical: ad hoc, ad hominem (borrowed from other languages)
Syntactical: wine and dine (exhibit peculiar syntactic behavior)
Semantic: spill the beans - reveal secret (figurative/metaphorical usage)
Basic tasks in MWE:
Extract collocations
Establish linguistic validity of collocation
Measure semantic decompositionality of the MWE
Various approaches to find collocation
A collocation is an expression consisting of two or more words that corresponds to a conventional way of saying things
Types:
Grammatical
Semantic
Flexible
Approaches:
Selection of collocations by frequency
Selection based on mean and variance of the distance between focal word and collocating word
Hypothesis testing
Mutual information
What is stemming? What Stemming can be used for preprocessing
Stemming:
It is a method of normalization of words in NLP
It is a technique in which a set of words in a sentence are converted into a sequence to shorten its lookup
Eg: the root word is ‘eat’ and its variations are ‘eats, eating, eaten and like so’
Porter Stemmer:
A simpler algorithm that doesn’t require the large on-line lexicon
Used in information retrieval
Removal of inflectional ending from the words
Eg: relational -> relate, motoring -> motor, grasses -> grass
Justify King - Male + Female = Queen
Word vectors:
Word vectors represent words as multidimensional continuous floating point numbers where semantically similar words are mapped to proximate points in geometric points
This means that words such as wheel and engine should have similar word vectors to the word vector of car whereas the word banana should be quite distant
The beauty of representing words as vectors is that they lend themselves to mathematical operators
For example, we can add and subtract vectors
In this canonical example, by using word vectors we can determine that King - Man + Woman = Queen

Comments
Post a Comment