18CSE484T - Deep Learning Unit 2 & 3 (12 MARKS)
12M:
Use case: Written character recognition → CNN
Description of the MNIST handwritten digit recognition problem:
The MNIST problem is a dataset for evaluating machine learning models on the handwritten digit classification problem
Each image is a 28 x 28 pixel square
A standard split of the dataset is used to evaluate and compare the models, where 60000 images are used to train the model and a separate set of 10000 images are used to test it
It is a digit recognition task. As such there are 10 digits or 10 classes to predict
Excellent results achieve a prediction error of less than 1%
Program:
# Larger CNN for the MNIST Dataset
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.utils import to_categorical
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32')
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]
# define the larger model
def larger_model():
# create model
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D())
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D())
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model = larger_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
Explain in details about the activation’s functions of deep learning network
Activation function:
The activation function decides whether a neuron should be activated or not
This means that it will decide whether the neuron’s input to the network is important or not in the process of prediction using simpler mathematical operations
Types of activation functions:
Binary step function
Linear function
Sigmoid function
Tanh function
Relu function
Leaky relu function
Parameterized relu function
Exponential linear unit
Binary step function:
If the input to the activation function is greater than the threshold value, then the neuron is activated, else it is deactivated
f(x) = 1 if x>=0 =0 if x<0
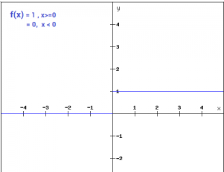
Gradient of binary step function:
f’(x) = 0 for all x
Since the gradient of the function is zero, the weights and biases don’t update
Linear function:
The activation is proportional to the input
f(x) = ax
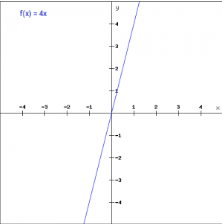
Gradient of linear function:
f’(x) = a for all x
Though the gradient is not zero, it is constant (does not improve error)
Sigmoid function:
Most widely used nonlinear activation function
Transforms the values between 0 and 1
f(x) = 1/ (1+e^-x)
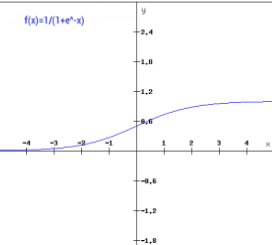
Gradient for sigmoid function:
f’(x) = sigmoid(x) * 1-sigmoid(x)
Tanh function:
Transforms the values between -1 and 1
f(x) = 2sigmoid(2x) - 1
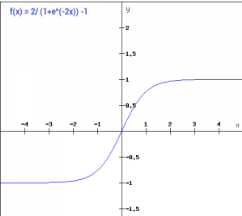
Gradient for tanh function:
f’(x) = 1 - tanh^2(x)
ReLU function:
ReLU stands for Rectified linear unit
The main advantage is that it does not activate all the neurons at the same time
f(x) = x if x>=0 f(x) = 0 if x<0
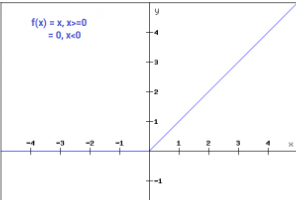
Gradient of ReLU function:
f(x) = 1 if x>0 f(x) = 0 if x<0
Leaky ReLU function:
Improved version of ReLU function
f(x) = x if x>=0 f(x) = 0.01x if x<0
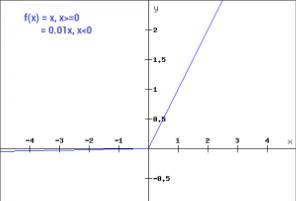
Gradient of leaky ReLU function:
f(x) = 1 if x>0 f(x) = a if x<0
Parameterized relu function:
To solve the problem of gradient becoming zero for the left half of the axis
f(x) = x if x>=0 f(x) = ax if x<0
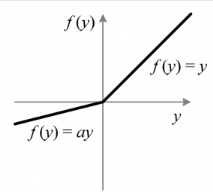
Gradient of parameterized ReLU function:
f(x) = 1 if x>0 f(x) = a if x<0
Exponential linear unit:
ELU uses a log curve for defining the negative values
f(x) = x if x>=0 f(x) = a * (e^x-1) if x<0
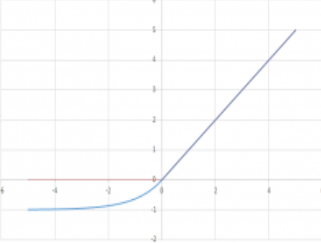
Gradient of ELU function:
f(x) = x if x>0 f(x) = a * (e^x) if x<0
Learning of XOR



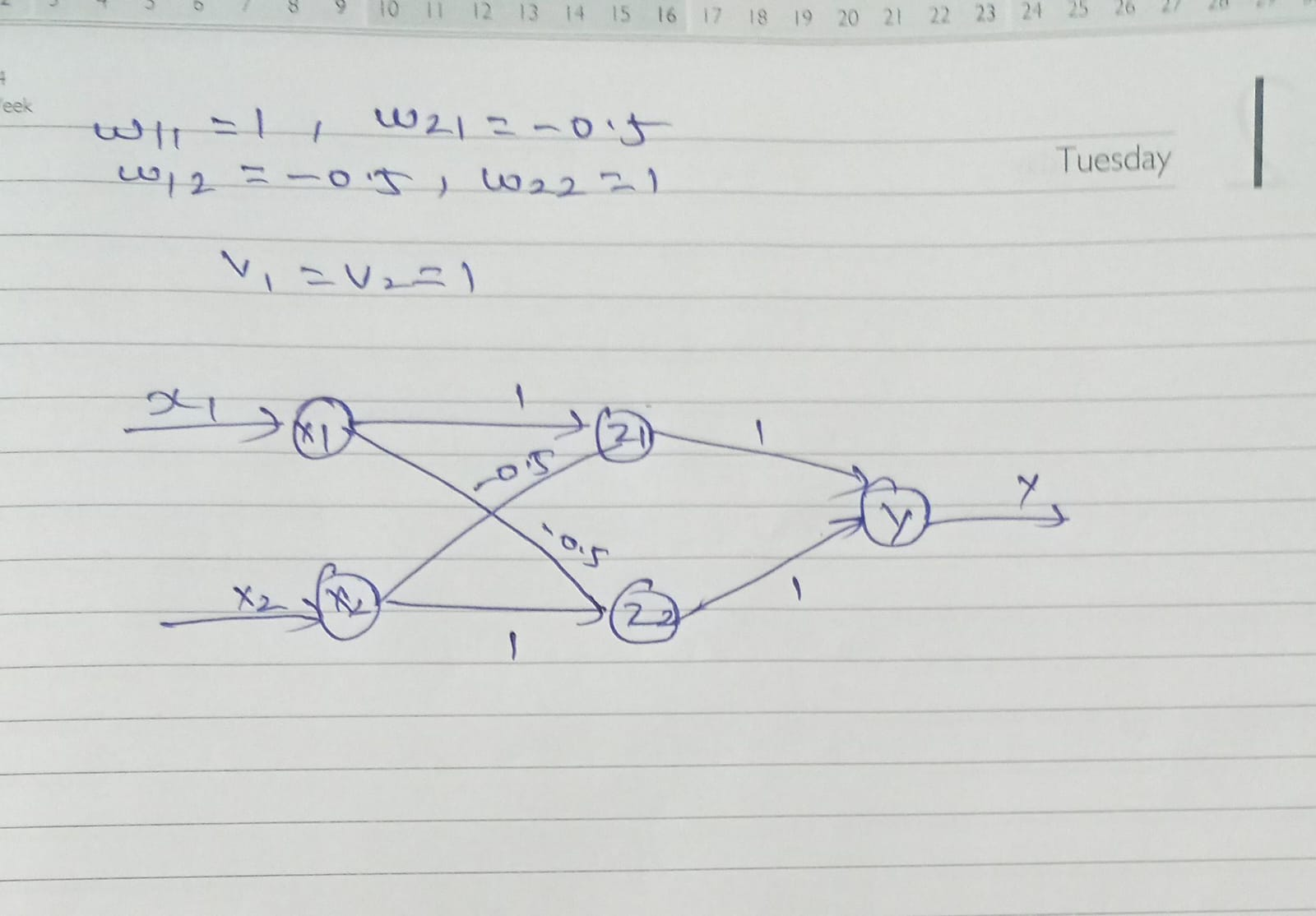
Explain how chain rule work for the deep learning
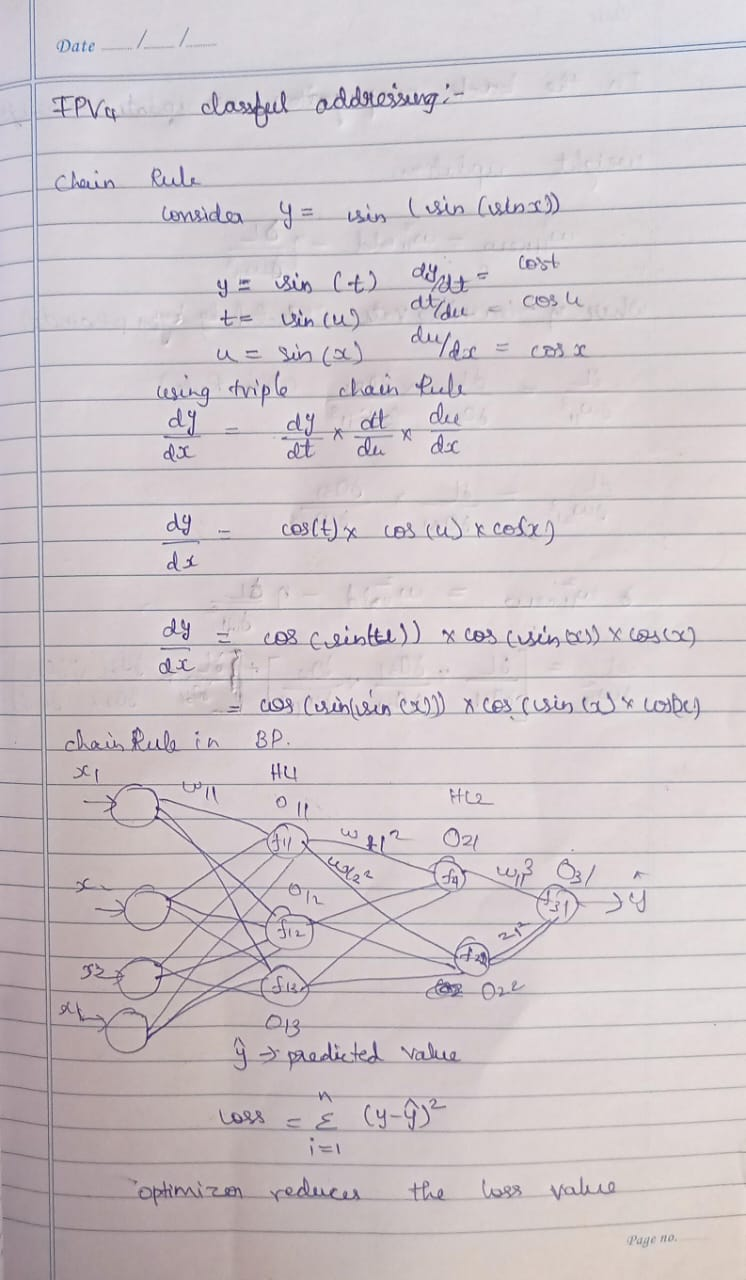

Write in detail about various optimization methods of deep learning
Optimizers are algorithms or methods used to change the attributes of the neural network such as weights and learning rate to reduce the loss
Optimizers are used to solve optimization problems by minimizing the function
Importance of learning rate:
Learning rate determines the size of the gradient steps into the direction of the local minimum
If too big, then local minimum may be skipped
If too small, then it may take a while to reach local minimum
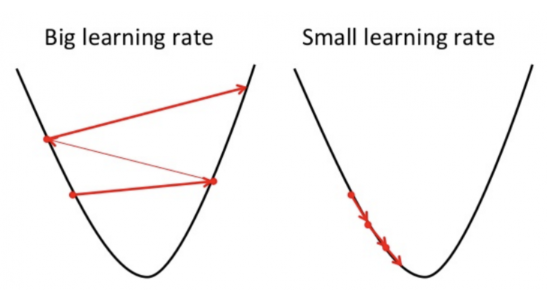
Gradient descent algorithm:
A gradient measures how much the output of a function changes if you change the inputs a little bit
gradient descent is an optimization algorithm for finding the local minimum of a differentiable function
Compute gradient until gradient is almost zero
Gradient descent is slow on huge data
Stochatic gradient descent:
SGD randomly picks one data point from the whole data set at each iteration to reduce the computations enormously
By iteratively updating the weights, the model aims to minimize the loss and improve its accuracy
Adaptive Gradient descent:
One of the disadvantages of optimizers is that the learning rate is constant for all parameters and each cycle
Adagrad changes the learning rate
It changes the learning rate ‘η’ for each parameter and at every time step ‘t’.
It works on the derivative of an error function.
It performs smaller updates for parameters associated with frequently occurring features, and larger updates for parameters associated with infrequently occurring features.
Adagrad keeps track of the sum of gradient squared
Root mean square propagation:
AdaGrad is incredibly slow, because the sum of gradient squared only grows and never shrinks.
RMSprop adds a decay factor.
Adaptive moment estimation:
Adam combines the advantages of two other extensions of stochastic gradient descent, specifically,
Adagrad
RMSprop
Instead of adapting the parameter learning rates based on average first moment as in RMSprop, adam also uses the average of the second moments
Beta 1 is the decay rate for the first moment (0.9)
Beta 2 is the decay rate for the second moment (0.999)
Adam gets the speed from the momentum and the ability to adapt gradients in different directions from RMSprop. This combination makes it powerful.
Convolution process illustration with an image and a kernel
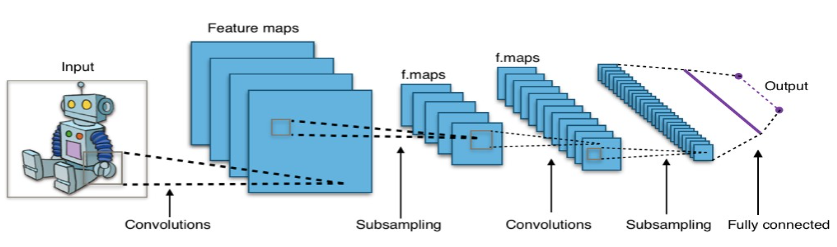
CNN Intro:
Type of deep learning architecture
Used for image classification and recognition tasks
CNN is a neural network with convolution operations instead of matrix multiplication in atleast one of the layers
Consists of
Convolutional layers (applies filters to the input image)
Pooling layers (downsamples the image)
Fully connected layers (makes the final prediction)
CNN architecture:
Example image matrix multiplies filter matrix:
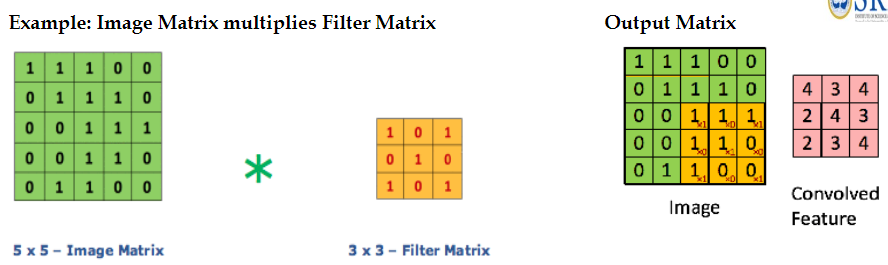
Convolution operation:
Assume that the input will be a color image, which is made up of a matrix of pixels in 3D
Image will have 3 dimensions - height, depth and width - which corresponds to the RGB in image
We also have a feature detector, also known as kernel or filter which moves receptive fields of the image, checking if the feature is present. This is called convolution
Types of filters:
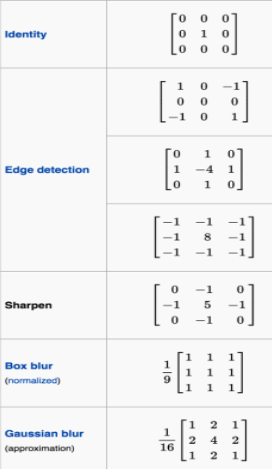
Pooling:
Convolutional layer apply filters to input images to create feature maps
Limitation of feature maps solved by downsampling approach
Reduces the dimensionality of images by reducing the number of pixels in the output from the previous convolutional layer
Types:
Max pooling
Average pooling

Comments
Post a Comment