18CSE484T - Deep Learning Unit 1
4M:
How to avoid overfitting and underfitting in a model?
Avoid Overfitting:
Cross-validation
Training with more data
Removing features
Early stopping the training
Regularization
Avoid Underfitting:
Increasing the training time of the model
Increasing the number of features
Ensembling
Increasing model complexity
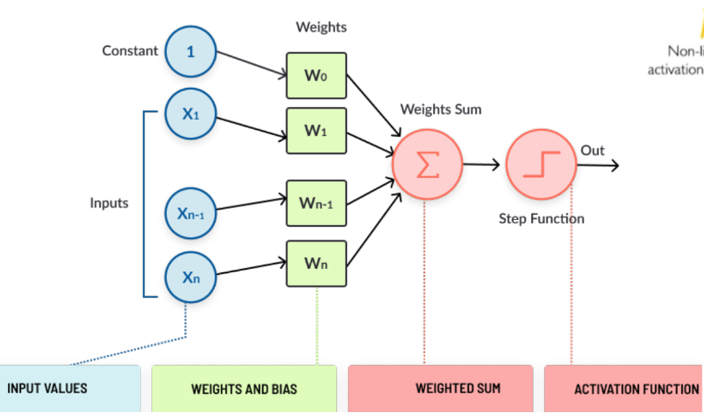
Illustrate the model of McCulloch Pitts Neuron
Warren McCulloch and Walter Pitts proposed a highly simplified computational model in 1943
The basic idea is that the neuron is either active or inactive
Binary input signals - x1, x2,...xn
Theta - thresholding parameter
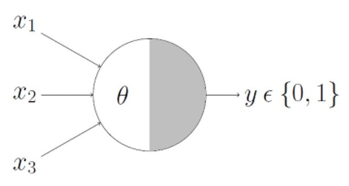
This representation just denotes that for the boolean inputs x1, x2, x3 if g(x) i.e sum>=theta, the neuron will fire otherwise it won’t
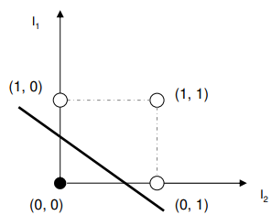
Write short notes about linear separability
Let ax+ by < c and ax+ by > c be two regions on the xy plane separated by the line ax+ by + c = 0
If we consider (x,y) as input point, then the perceptron tells us which region this point belongs to
These regions which can be separated by a single line are called linear separable regions
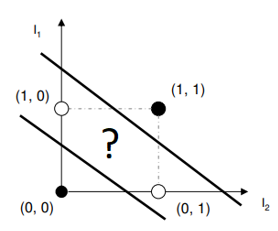
For example, OR is linearly separable whereas XOR is non-linearly separable
OR:
XOR:
Compare and contrast single layered model and multi layered perceptron model.
Write in brief about Supervised and Unsupervised Learning
Supervised Learning
Supervised learning is a type of machine learning algorithm that learns from labeled data.
Labeled data is data that has been tagged with a correct answer or classification
The machine learns the relationship between the inputs and the outputs and can then make predictions on new, unlabeled data
Types:
Regression
Classification
Unsupervised Learning
Unsupervised learning is a type of machine learning algorithm that learns from unlabeled data.
Unlabeled data does not have any pre-existing labels or categories
The goal of unsupervised learning is to discover patterns and relationships in the data without any explicit guidance
Types:
Clustering
Association
Explain the significance of dimensionality reduction
It is a process of transforming a dataset from a high dimensional space to a low dimensional space whilst maintaining its informational integrity for predictive modeling
Why is it important?
Alleviate the curse of dimensionality
Computationally less expensive
Easier to visualize data
Removes noise from dataset
Increase in machine learning model performance
Why is the Bias-Variance trade-off important?
Bias is the difference the average of the predicted values and the actual value at that point
Variance quantifies how scattered or how much variation there is from the true value
The bias variance tradeoff is a central problem in supervised learning
Ideally, one wants a model that can accurately capture the regularities in its training data but also generalizes well to unseen data
Unfortunately it is typically impossible to do both simultaneously
High bias leads to underfitting and low variance leads to underfitting
Striking the right balance between bias and variance ensures accurate predictions while avoiding overfitting or underfitting
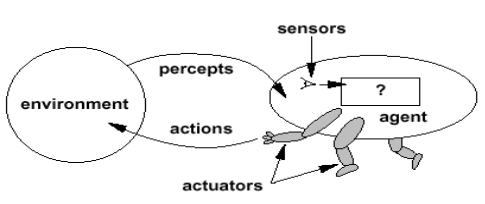
How does the biological neuron inspire the construction of an artificial neuron?
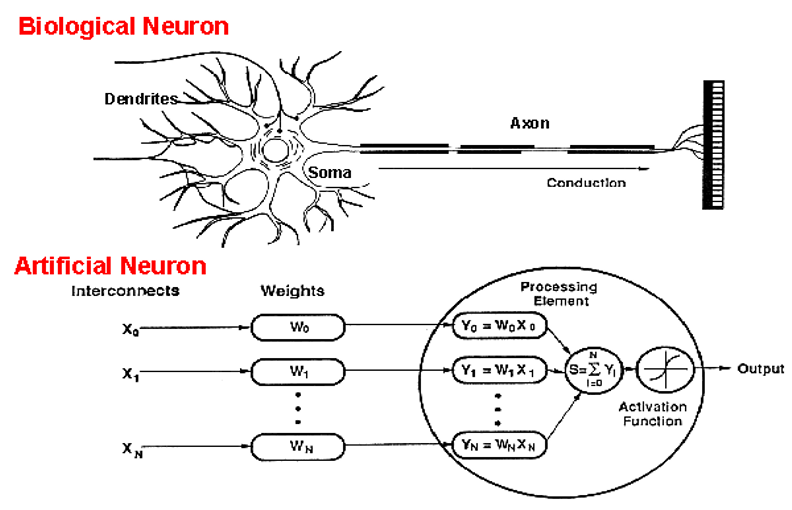
An artificial neuron is an imitation of a human neuron
Inputs are fed into the hidden layer along with weights
It is then processed and and sent to the output layer
The output is then passed on to the next neuron
12M:
Illustrate Backpropagation algorithm working with a sample classification problem.
Backpropagation algorithm:
Inputs x arrive through preconnected path
The input is modeled using true weights W. the weights are usually chosen randomly
Calculate the output of each neuron from the input layer to the hidden layer to the output layer
Calculate the error in the outputs (Backpropagation error = actual output - desired output)
From the output layer, go back to the hidden layer to adjust the weights to reduce the error
Repeat the process until the desired output is achieved
For example problem:
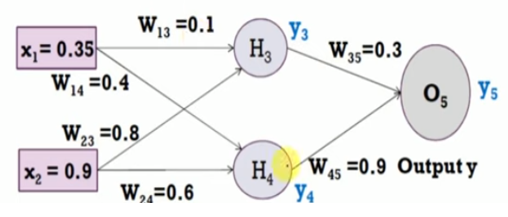
Learning rate = 1
Output - 0.5
Sigmoid function - 1 / 1+ e^-x
Write the various cross validation techniques meant for testing the model
Cross validation is a resampling technique with the fundamental idea of splitting the dataset into 2 parts - training data and testing data
Train data is used to train the model and the unseen test data is used for prediction
Hold out method
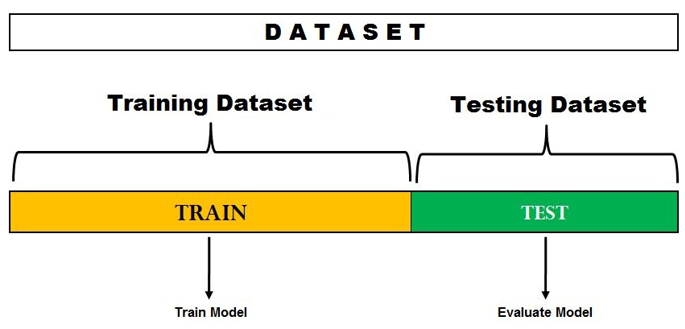
Simplest evaluation method and widely used
The entire dataset is divided into 2 sets - train set and test set
The proportion of training data has to be larger than the test data
Leave one out cross validation
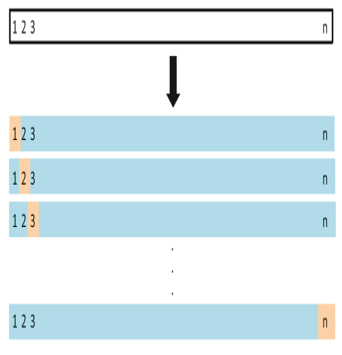
Instead of dividing the data into 2 subsets, we select a single observation as test data and everything else is labeled as training data and the model is trained
Next the 2nd observation is selected as test data and the process is repeated
K-fold cross validation
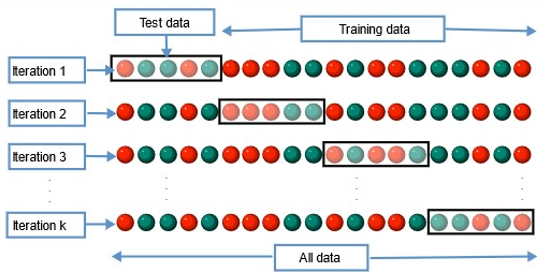
The whole data is divided into k sets of almost equal sizes
The first set is selected as test set and the model is trained on the remaining k-1 sets
The test error rate is then calculated
This process continues for all the k sets
Stratified k-fold cross validation
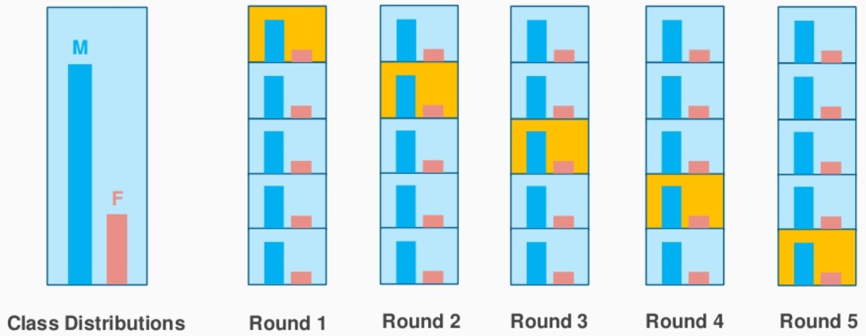
Slight variation from the k-fold validation which uses ‘stratified sampling’ instead of ‘random sampling’
Data is split in such a way that it represents all the classes from the population
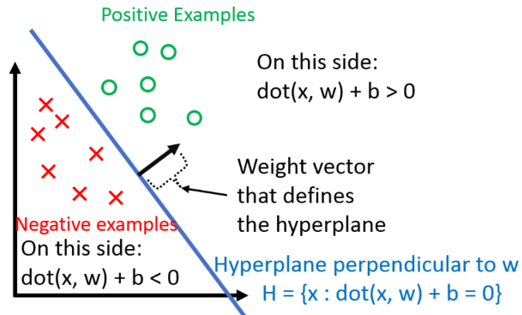
Write and explain the perceptron learning algorithm OR Explain the convergence theorem for the perceptron learning algorithm
The Perceptron: Forward propagation
Perceptron Learning algorithm

The algorithm converges only when all the inputs have been classified correctly
Taking any random input x, we check whether it belongs to class P or class N
If it class P and input multiplied by weight is less than 0, then weight w is updated as the weight + input
If it class N and input multiplied by weight is greater than or equal to 0, then weight w is updated as the weight - input
This is repeated until the algorithm converges
Perceptron Convergence Theorem:
For any finite set of linearly separable labeled examples, the perceptron learning algorithm will halt after a finite number of iterations
In other words, after a finite number of iterations, the algorithm yields a vector w that classifies all the examples perfectly
We are interested in finding the line that divides the input space into two halves
The angle between vector w and a point x on the line is 90
But for input in class P, the angle is less than 90 and for input in class N, it is viceversa
That is why in the perceptron learning algorithm we add and update the weight for class P and for class N we subtract and update the weight

Comments
Post a Comment